-
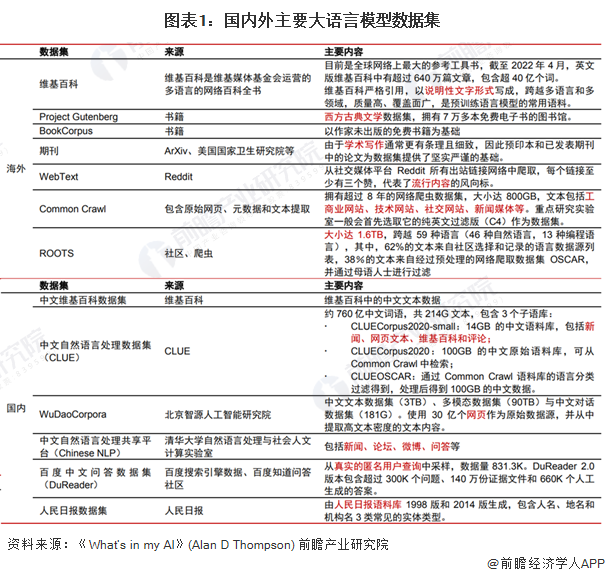
国内外主要大语言模型数据集
发布时间:2024-10-28
得益于开源共创的互联网生态,海外已有大量优质、结构化的开源数据库,文本来源既包含严谨的学术写作、百科知识,也包含文学作品、新闻媒体、社交网站、流行内容等,更加丰富的语料数据能够提高模型在不同情景下的对话能力。而受制于搭建数据集较高的成本以及尚未成熟的开源生态,国内开源数据集在数据规模和语料质量上相比海外仍有较大差距,数据来源较为单一,且更新频率较低,从而导致模型的训练效果受限。因此,大模型厂商的自有数据和处理能力构成模型训练效果差异化的核心。受益于移动互联网时代积累的海量用户、应用和数据,互联网企业在自有数据上更具特色化和独占性,叠加更强大的数据处理能力,从而能够通过数据优势带来模型训练成果的差异。例如,阿里在研发M6时,构建了最大的中文多模态预训练数据集M6-Corpus,包含超过1.9TB图像和292GB文本,涵盖百科全书、网页爬虫、问答、论坛、产品说明等数据来源,并设计了完善的清洁程序以确保数据质量。百度ERNIE模型的训练数据集中也运用了大量百度百科、百度搜索以及百度知识图谱等生态内数据,通过更高质量的数据保障了模型的训练效果。