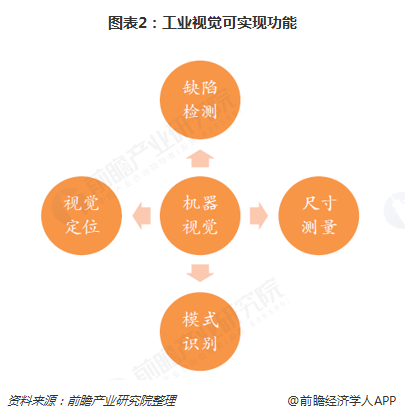
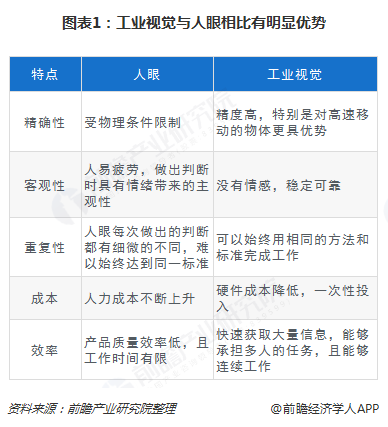
-
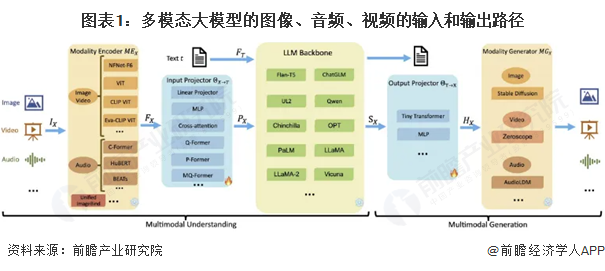
多模态大模型的图像、音频、视频的输入和输出路径
发布时间:2025-06-01
多模态大模型的探索正在逐步取得进展,近年来产业聚焦在视觉等重点模态领域突破。理想中的“Any-to-Any”大模型,Google Gemini、Codi-2等均是处于探索阶段的方案,其最终技术方案的成熟还需要在各个模态领域的路线跑通,实现多模态知识学习,跨模态信息对齐共享,进而实现理想中多模态大模型。现阶段产业主要的工作还是聚焦在视觉等典型的重点模态,试图将Transformer大模型架构进一步在图像、视频、3D模型等模态领域引入使用,完善各个模态领域的感知和生成模型,再进一步实现更多模态之间的跨模态打通和融合。