-
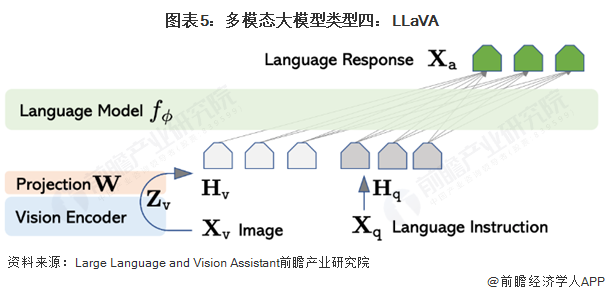
多模态大模型类型四:LLaVA
发布时间:2025-05-22
使用视觉编码器CLIP ViT-L/14+语言解码器LLaMA构成多模态大模型,然后使用生成的数据进行指令微调。输入图片X经过与训练好的视觉编码器的到图片特征Z,图片特征Z经过一个映射矩阵W转化为视觉Token H,这样Vison Token Hv与Language Token Hq指令就都在同一个特征空间,拼接后一起输入大模型。这里的映射层W也可以替换为更复杂的网络来提升性能,比如Flamingo中用的gated cross-attentio,BLIP-2中用的Q-former。