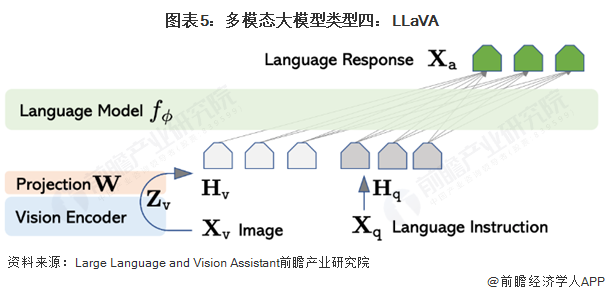
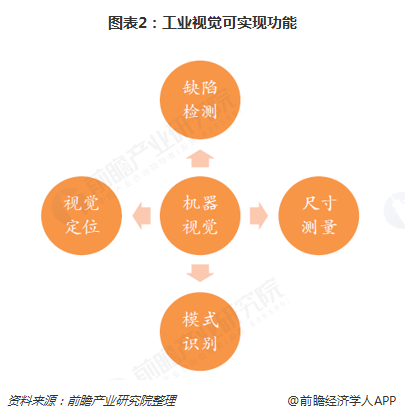
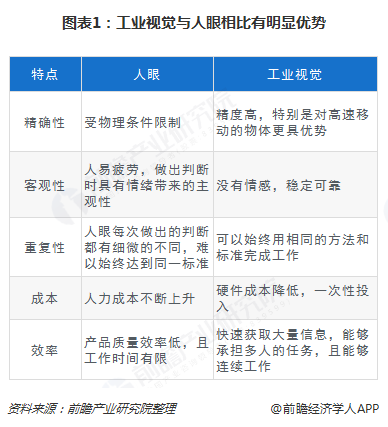
-

多模态大模型类型一:CLIP
发布时间:2025-05-22
CLIP是OpenAI提出的连接图像和文本特征表示的对比学习方法。CLIP是利用文本信息训练一个可以实现zero-shot的视觉模型。利用预训练好的网络去做分类。具体来说,给网络一堆分类标签,比如cat,dog,bird,利用文本编码器得到向量表示。然后分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果。论文提到,相比于单纯地给定分类标签,给定一个句子的分类效果更好。比如一种句子模板A photo of a.,后面填入分类标签。这种句子模板叫做 prompt(提示)。句子模板的选择很有讲究,还专门讨论了prompt engineering,测试了好多种类的句子模板。提示信息有多种,下图可以看到它用不同的类别替换一句话中不同的词,形成不同的标签。